
Покемоны в статистике
«Gotta catch 'em all!»
song by John Siegler and John Loeffler and performed by Jason Paige
Концепция проекта
Вселенная Pokémon
— является одной из самых популярных франшиз видеоигр и аниме. Коллекционирование особых существ — покемонов, обитающих в мире похожем на наш, является основной темой франшизы. Возможность иметь необычного питомца, становиться сильнее и вступать в схватки с другими тренерами покемонов всегда покоряла меня и захватывала воображение самыми разными размышлениями. «Кто самый сильный покемон?», «Чем они друг от друга отличаются?» и многие другие вопросы наконец нашли свои ответы с обнаружением датасета со всеми внутриигровыми показателями каждого из 721 существа, представленного в датасете.Для анализа был выбран датасет Pokemon with stats найден на сайте Kaggle.
Для визуализации данных были я выбрала следующие типы графиков:
1. Гистограмма — для выражения убывания количества представителей вида. 2. Линейный график — для наглядности эскалации и деэскалации силы. 3. Диаграмма рассеивания — для обозначения множества объектов, имеющих несколько характеристик путем расположения на графике и размера обозначенной точки. 4. Линейная диаграмма — для визуализации иерархичности показателей. 5. Тепловая карта — для выявления наибольших корреляций путем контраста цветов.
Для анализа данных, работе с датасетом и написания кода для графиков я использовал нейросеть DeepSeek. Промпты будут представлены вместе с исходным файлом GoogleCollab.
Обработка данных
Для полноценной работы мне понадобились библиотеки pandas, numpy, matplotlib.pyplot, seaborn, kagglehub и os.
Через библиотеку kagglehub я подключая датасет с сайта Kaggle напрямую, далее нахожу csv файл и подключаю в датафрейм pandas. И наконец данные просматриваются.
Удаляю дубликаты и преобразую типы данных для последующего анализа.
Форматы визуализации
Изучающий формат визуализации
На примере одного из блоков данных для составления графика, я продемонстрирую изучающий и обучающий форматы данных.
Цель в ниже приведенных графиках была в подсчете и выявлении лидеров в категориях Type1 и Type2, относящихся к типу стихий конкретных покемонов. Изучающий формат позволяет собрать массив данных по разным графиком, с учетом разных переменных и облегчает дальнейшее создание обучающего формата данных.
1. Линейчатая гистограмма с учетом Type1 2. Круговая диаграмма с выявлением топ-10 3. Линейчатая гистограмма с учетом Type1 и Type2

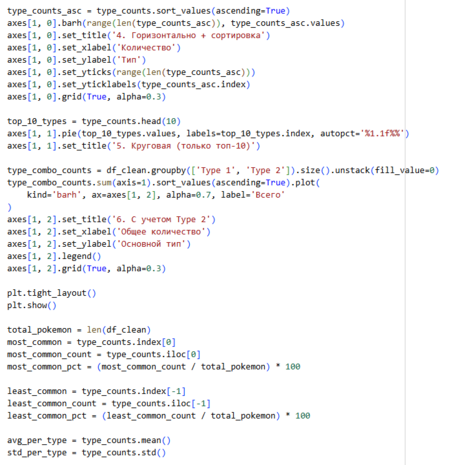
Код к вышеприведенным графикам.
Обучающий формат визуализации
Чтобы не повторяться с последующими графиками, ниже представлена версия графика с измененной палитрой и инфографикой. Здесь мы можем видеть как статистические данные представлены в текстовом контексте и имеются дополнительные маркеры выводов, полученных при анализе датасета.Столбчатая диаграмма, наполненная статистическими заключениями.
Основные статистические методы
Частотный анализ и процентное распределение
type_counts = df_clean['Type 1'].value_counts () type_percentages = (type_counts / total_pokemon * 100).round (1)
top_15 = df_clean.nlargest (15, 'Total')
generation_counts = df_clean['Generation'].value_counts ().sort_index ()
Метод нашел применение практически во всех графиках и используется для подсчета наблюдений в каждой из категорий, удобен тем, что позволяет сразу увидеть лидеров и отстающих к категориях.
Агрегация данных и группировка
legendary_group = df_clean[df_clean['Legendary'] == True] normal_group = df_clean[df_clean['Legendary'] == False]generation_avg = df_clean.groupby ('Generation')['Total'].mean ()
df_top_types = df_clean[df_clean['Type 1'].isin (top_types)]
Объединение данных по группам очень удобно для дальнейшего сравнения.
Корреляционный анализ и взаимосвязи
correlation_matrix = df_clean[['HP', 'Attack', 'Defense', 'Total']].corr ()Defense plt.scatter (df['Attack'], df['Defense'])
sns.lineplot (x='Generation', y='Total', data=generation_avg)
Сравнение и выявление различий и взаимосвязей между переменными являются основой статистики в половине из графиков.
Итоговые графики

Определяющий тип
Каждый покемон имеет тип, который характеризует его способности и делает уязвимым или наоборот устойчивым к атакам других типов, это определяется внутриигровыми правилами. Но так как вселенная Pokémon старается походить на нашу, то и скажем Драконий тип не будет так же распространен, как и Обычный. Так же в учет идет то, что покемоны могу иметь два типа одновременно.Я выявила наиболее и наименее распространенные типы покемонов, учитывая тех, что имеют один тип и тех, что имеют два. На удивление наиболее распространенным оказался Водный тип, а наименее Летающий, что выглядит не совсем реалистичным.
Связь поколений
Так же покемоны делятся на поколения, соответственно поколениям выхода видеоигр. С увеличением количества необычных существ, фаворитизм фанатов начал создавать когнитивный диссонанс о превосходстве одного поколения покемонов над другим. Может это связано с синдромом утенка или же просто с тем, что новые игры и сезоны мультсериала уже не интересуют старых фанатов, но статистика показывает что средний показатель Общей Силы — суммы всех показателей покемона не имеет серьезных различий из поколения в поколение.На момент создания найденного датасета, в него внесены только 6 первых поколений.
Линейный график с измерением средней силы на поколение.
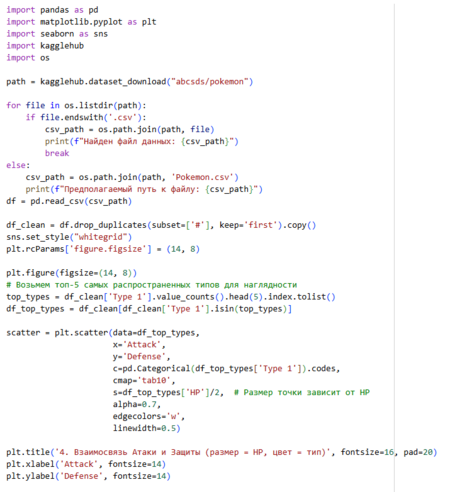
Показательные кластеры
Извечный вопрос: «Какие показатели нужно приоритизировать при выборе своего спутника? И можно ли жертвовать скажем атакой в силу защиты? Есть между независимыми друг от друга показателями корреляция по статистике?» Данный график наглядно показывает, что например покемоны с высокой Атакой часто имеют низкую Защиту или наоборот низкую Атаку и высокий показатель Здоровья.Диаграмма рассеивания. Величина точек показывает количество Здоровья.

Кто сильнейший?
Показатель общей силы, часто является основным показателем при решении кому же из своих любимцев отдать предпочтение в первую очередь. Ниже приведен график сильнейший покемонов на момент 6 поколения.Линейчатая диаграмма с сильнейшими покемонами и их типами.
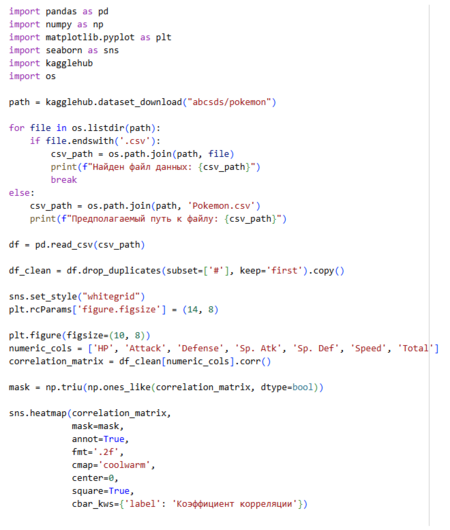
Характеристика по корреляциям
Углубляясь в тему взаимосвязей показателей питомцев и влияния этого на их выбор, было решено дополнить список графиков, финальным с полной корреляцией всех показателей друг к другу.На основе данных можно сделать интересные выводы, о том, что чаще всего высокая Защиты замедляет, а высокий показатель Атаки скорее всего будет означать более быстрого покемона.
Тепловая карта корреляций показателей друг с другом.
Заключение
Собранные и проанализированные данные подарили мне чувство ностальгии и большей осознанности своего детства. Со временем подход к восприятию видеоигр, особенно тех, с персонажами которых вы строите крепкую связь, координально меняется.
Но теперь с собранными данными, я с радостью вернусь с игры детства и постараюсь применить статистические заключения для лучшего геймплея.
Описание применений нейросетей
DeepSeek — для помощи написания кодов для графиков.



